


Introduction
Quantitative finance has traditionally relied heavily on statistical and econometric models to forecast market fluctuations. These models use mathematical methods, grounded in advanced probability theory, such as time-series models, continuous-time stochastic processes, or Monte Carlo simulations to optimise the returns on investments or trades in an ever-changing financial landscape. However, these models – resembling multivariate linear regression models- are inherently limited by their assumption of linear relationships. This concept, introduced by Carl Friedrich Gauss in an 18th century work on geodesic and astronomical datasets[1].
Michal Andrzejewski
Sources and End Notes
Photo by XK Studio from Pexels: https://www.pexels.com/photo/an-artist-s-illustration-of-artificial-intelligence-ai-this-image-depicts-agi-artificial-general-intelligence-s-potential-to-enrich-lives-it-was-created-by-xk-studio-as-part-of-the-v-18069832/. Submitted on August 21st, 2023
- Lopez de Prado, M. (2018, October 20). Advances in Financial Machine Learning: Lecture 1/10 (seminar slides) [Presentation slides]. Cornell University ORIE 5256. Retrieved from https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3252423}, is inadequate for today’s complex, data-driven financial systems.
With the rise of machine learning, a new influx of powerful methods has entered the field. These techniques offer the ability to capture much more complex, nonlinear relationships in vast datasets, addressing some limitations of traditional models\footnote{López de Prado, Marcos. Machine Learning for Asset Managers. United States, Cambridge University Press, 2020.}. This shift reflects both the technological progress and the growing demand for methods capable of handling the current dynamic, intricate financial systems. These structures require a larger number of predictors than the purely econometric approaches were able to analyse. The machine learning algorithms allow predictions based on diverse data sources beyond classic financial statements. They include patterns found in alternative sources like the news, credit card transactions, or social media. As a result, these algorithms are exposed to a broader range of inputs to draw from, offering richer insights into market sentiment and behavior\footnote{Zhang, Zihao, Stefan Zohren, and Stephen Roberts. Deep Reinforcement Learning for Trading. Department of Engineering Science, Oxford-Man Institute of Quantitative Finance, University of Oxford, 2020.}, outperforming traditional methods, when trained on sufficiently large datasets, as shown in Figure fig:comparison – making them attractive tools for modern trading.
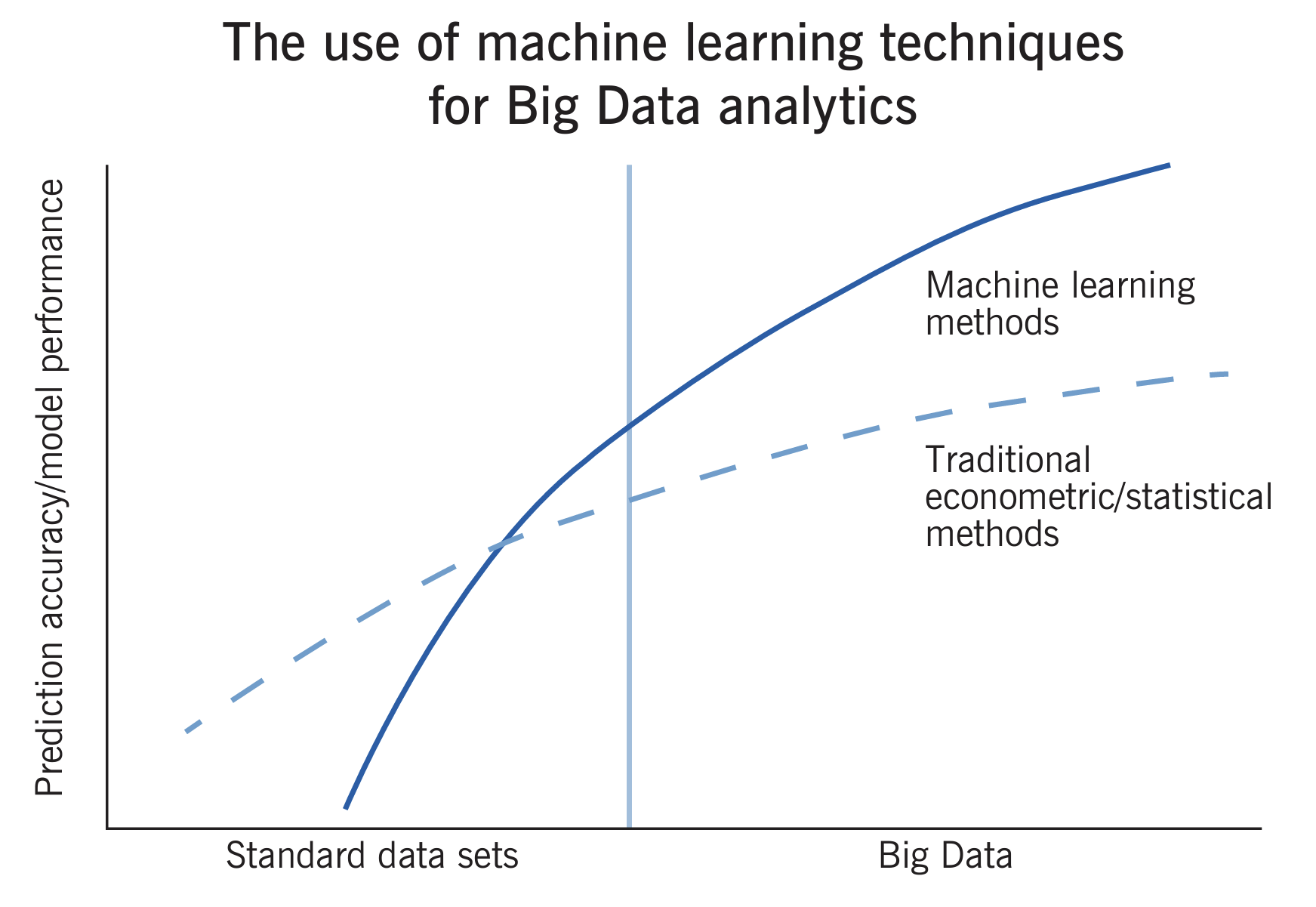
Figure 1. Performance Comparison of Machine Learning and Econometric Methods. Source: Harding, M., Hersh, J. Big Data in economics. <span class="latex_it">IZA World of Labor</span> 2018: 451 doi: 10.15185/izawol.451 Machine Learning in Algorithmic Trading
Algorithmic trading now accounts for around 75
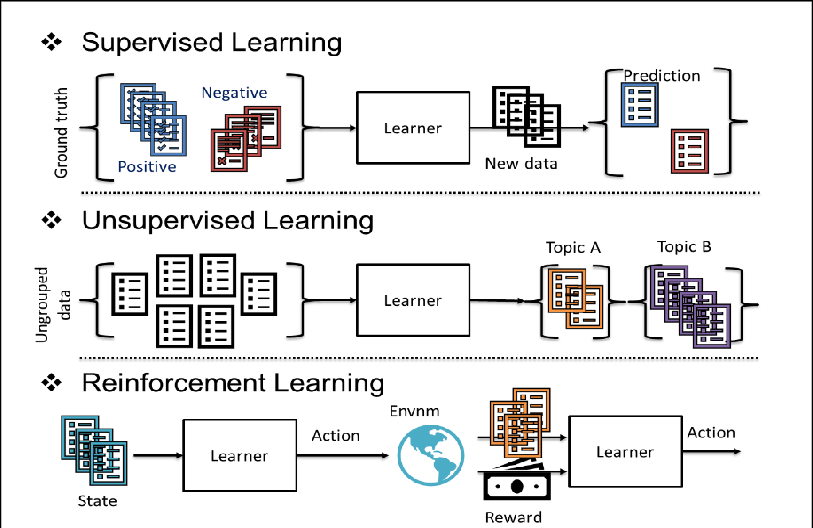
Figure 2. Machine Learning Paradigms in Quantitative Finance. <span class="latex_it">Source:Koshiyama, Adriano Firoozye, Nick Treleaven, Philip. (2020). Algorithms in Future Capital Markets. SSRN Electronic Journal. 10.2139/ssrn.3527511. </span>
Among these three, reinforcement learning (RL) has become particularly promising by allowing an agent (the trading algorithm) to learn optimal strategies through continuous interaction with the environment (the financial market), without a priori assumptions about its dynamics, leading to rapid progress in adapting RL techniques in algorithmic trading \footnote{Hambly, B., Xu, R., Yang, H. (2022). Recent Advances in Reinforcement Learning in Finance. February 3, 2022.}.Methods of Reinforcement Learning
Reinforcement learning (RL) algorithms, widely applied in markets such as FX, cryptocurrency, or stocks, can be categorized as policy-based, hybrid (e.g., actor-critic), or value-based. Value-based methods are relevant in contemporary trading strategies. Their construction involves defining a Markov Decision Process (MDP) aligned with the trading objective. Two main approaches are commonly used:
Infinite Time Horizon with Discounted Rewards used usually for Portfolio Optimization
\begin{equation}
V(s) = \sup_{\pi} \mathbb{E}^{\pi} \left[ \sum_{t=0}^{\infty} \gamma^t r(s_t, a_t) \mid s_0 = s \right]
\label{eq:infinite_time_horizon}
\end{equation}
.Finite Time Horizon with Terminal Reward, typically for High-Frequency Trading.
\begin{equation}
V_t(s) = \sup_{\pi} \mathbb{E}^{\pi} \left[ \sum_{u=t}^{T-1} r(s_u, a_u) + r_T(s_T) \mid s_t = s \right]
\label{eq:finite_time_horizon}
\end{equation}These value functions for each strategy are dependant on the state s, the action a, and the discount factor corresponding to the respective 5-tuple ( (S, A, P, R, [0;1]) ) of the MDP, with ( P ) and ( R ) representing the transition probabilities and the reward function. \footnote{Y. Li, “Deep reinforcement learning: An overview,” arXiv preprint arXiv:1701.07274, 201}
Having the MDP established, we can apply value-based methods such as Q-learning, which aims to identify an optimal policy by estimating the Q-function, ( Q(s, a) ), an extension of the value function that also incorporates the reward for action ( a ) in state ( s ) and then following the optimal policy thereafter\footnote{Watkins, C. J. C. H., \& Dayan, P. (1992). Q-learning. Machine Learning, 8(3-4), 279-292.}.
\begin{equation}
Q(s, a) = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t r(s_t, a_t) \mid s_0 = s, a_0 = a \right]
\end{equation}To iteratively update ( Q(s, a) ), Q-learning relies on the Bellman equation \footnote{Bellman, R. (1957). The Theory of Dynamic Programming.}:
\begin{equation}
Q(s, a) \leftarrow Q(s, a) + \alpha \left[ r(s,a) + \gamma \max_{a’} Q(s’, a’) – Q(s, a) \right]
\end{equation}Here, incorporating also the learning rate.
The Q-learning algorithm follows these steps\footnote{Hambly, B., Xu, R., Yang, H. (2022). Recent Advances in Reinforcement Learning in Finance}:

Through repeated application, this algorithm approximates the optimal Q-function converging towards an optimal trading policy. However, it has limitations in financial markets where the action space evolves every second \footnote{Bacoyannis, V., et al. Idiosyncrasies and Challenges of Data-Driven Learning in Electronic Trading. arXiv preprint, 2018.}, necessitating manual adjustments of MDP parameters and limiting full autonomy in real-time trading.
The Promise of Deep Reinforcement Learning
Following the introduction of the Deep Q-network (DQN)\footnote{Mnih, V., Kavukcuoglu, K., Silver, D. et al. Human-level control through deep reinforcement learning. Nature 518, 529–533 (2015). https://doi.org/10.1038/nature14236}, which efficiently handles high-dimensional inputs using deep neural networks, researchers have focused on parameterizing value functions and policies, including approximating the transition and reward functions within the Markov Decision Process (MDP) framework.\footnote{Hambly, B., Xu, R., Yang, H. (2022). Recent Advances in Reinforcement Learning in Finance. February 3, 2022.}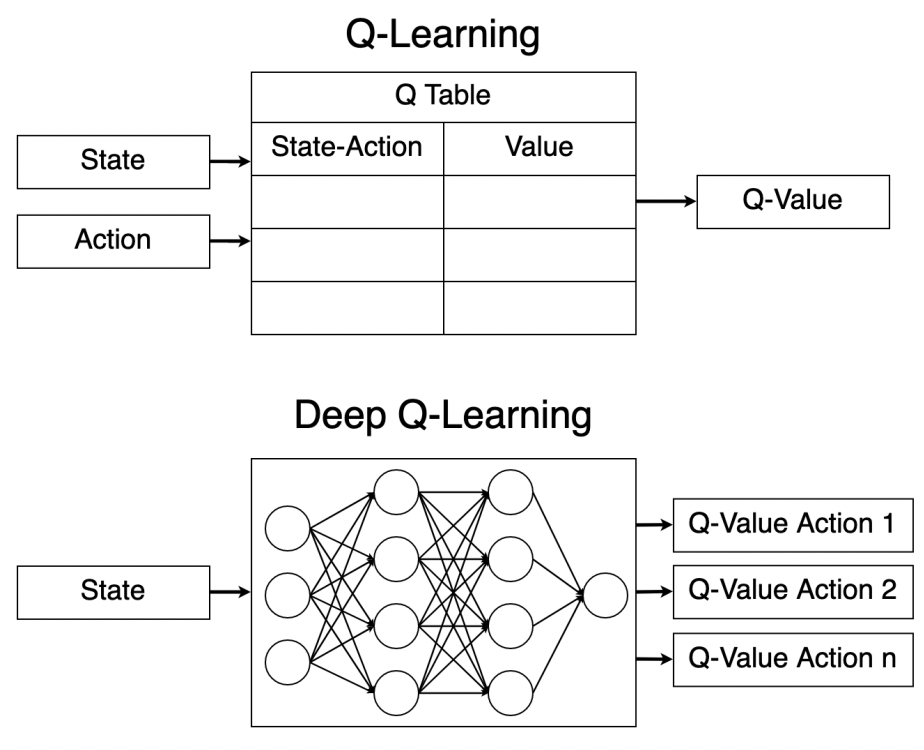
Figure 3. Comparison of Q-learning vs Deep Q-learning. Source: Sebastianelli, A., Tipaldi, M., Ullo, S., Glielmo, L. (2021). « A Deep Q-Learning Based Approach Applied to the Snake Game. In DQN, the Q-value function is approximated by a neural network with parameters, where the loss function used to train the network is the mean-squared error between predicted and target Q-values\footnote{Alvaro Cartea, Sebastian Jaimungal, and Leandro Sánchez-Betancourt, Deep Reinforcement Learning for Algorithmic Trading}:
\begin{equation}
L(\theta) = \mathbb{E} \left[ \left( y_t – Q(s_t, a_t; \theta) \right)^2 \mid (s_t, a_t, r_{t+1}, s_{t+1}) \right]
\end{equation}with the target computed using periodically updated target network parameters:
\begin{equation}
y_t = r_{t+1} + \gamma \max_{a’} Q(s_{t+1}, a’; \theta^-)
\end{equation}In recent years, the application of neural networks has increased. They range from simple fully-connected neural networks (FNN) to more sophisticated recurrent convolutional neural networks (RCNN), in which algorithmic trading has garnered attention. Many studies suggest that variations of DQN, which replace the conventional Q-table with neural networks to approximate Q-values (as depicted in Figure fig:deepq), offer considerable advantages in financial markets due to their ability to generalize complex patterns in financial data and autonomously adapt to changes occurring in them.
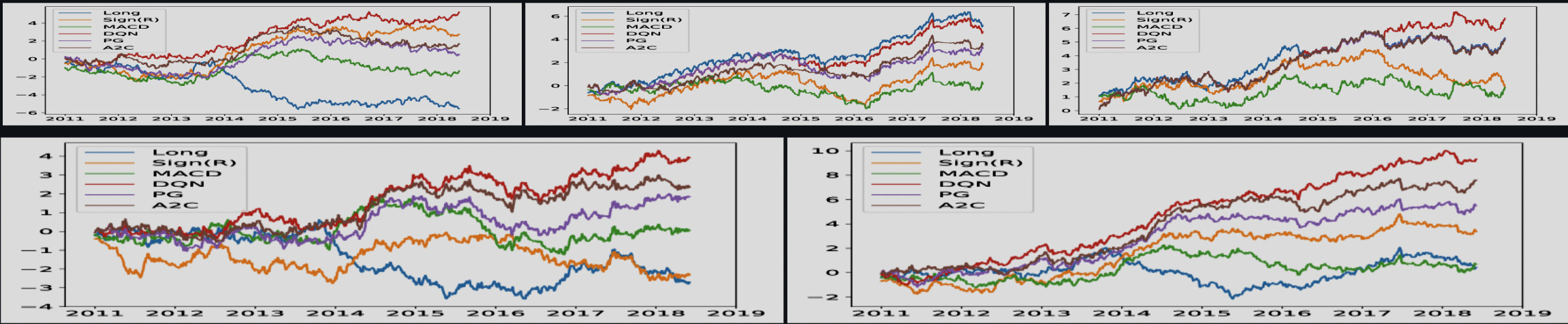
Figure 4. Cumulative trade returns from the paper « Deep Reinforcement Learning for Trading » by Zhang et al. First row: commodity, equity index, and fixed income; second row: FX and portfolio of all contracts. Papers such as Deep Reinforcement Learning for Trading\footnote{Zhang, Zihao, Zohren, Stefan, & Roberts, Stephen. (2020). Deep Reinforcement Learning for Trading. The Journal of Financial Data Science, 2(2), 25-40. https://doi.org/10.3905/jfds.2020.1.030} present in their experiments how DQN can outperform other methods in cumulative trade returns for various markets (commodity, equity index, fixed income, FX, and portfolio optimization) . In other papers, which specify slightly different environments and objectives, we can see its’ cousin algorithm, Deep Recursive Q-learning (DRQN) showing superior performance\footnote{Chen, L., and Gao, Q. « Application of Deep Reinforcement Learning on Automated Stock Trading. » 2019 IEEE 10th International Conference on Software Engineering and Service Science (ICSESS), IEEE, 2019, pp. 29-33. https://doi.org/10.1109/ICSESS47205.2019.9040728.}, as has Proximal Policy Optimization (PPO) in high-frequency trading\footnote{Briola, Antonio, et al. « Deep Reinforcement Learning for Active High Frequency Trading. » arXiv, 2021. https://doi.org/10.48550/arXiv.2101.07107.}. In sentiment analysis applications, models combining Deep Deterministic Policy Gradient (DDPG) with RCNN have also shown promising results.\footnote{Azhikodan, Akhil, et al. « Stock Trading Bot Using Deep Reinforcement Learning. » Lecture Notes in Electrical Engineering, vol. 505, 2019. https://doi.org/10.1007/978-981-10-8201-6_5.} Yet, while these studies outline impressive gains, it’s crucial to avoid idealizing DRL agents, as their actual effectiveness may vary in live, unpredictable market settings.
Conclusions and Concerns
Deep Reinforcement Learning (DRL) algorithms are powerful tools with immense potential in algorithmic trading. They show high performance and flexibility, grounded in strong capabilities for recognizing patterns and adapting dynamically to data from diverse sources. These algorithms offer promising pathways for financial applications as the technology advances. Nonetheless, the growing popularity of AI has fostered a layer of perceived mysticism and infallibility, sometimes overshadowing critical flaws in current research.
While DRL algorithms demonstrate strong performance in backtesting environments, they often struggle to deliver consistent results in live market conditions\footnote{Pricope, Tidor-Vlad. « Deep Reinforcement Learning in Quantitative Algorithmic Trading: A Review. » 2021. arXiv, doi:10.48550/arXiv.2106.00123.}.This discrepancy stems from overfitting, instability, and poor generalisation in real-time trading scenarios\footnote{Millea, A. « Deep Reinforcement Learning for Trading—A Critical Survey. » Data, vol. 6, no. 11, 2021, p. 119, doi:10.3390/data6110119.}. Although historical backtests may showcase favorable results, the models frequently falter under unpredictable market conditions. This trend of focusing on idealised backtest results, while downplaying real-world failures, is a consistent critique of DRL applications in finance.
While DRL-based algorithms hold « revolutionary » potential for trading strategies, it is important to recognize that the true factors enabling success in algorithmic trading are access to high-quality market data, computational power, and the structured preprocessing of this data to train algorithms effectively. As these algorithms assume greater control over substantial asset values, their transparency becomes essential to mitigate the risks associated with “black-box” models operating on a global scale. A malfunction or misinterpretation could have far-reaching consequences, potentially destabilizing markets in times of economic distress. Consequently, it is equally vital to consider the regulatory framework in which these algorithms operate, ensuring compliance to minimize risks of market manipulation and regulatory failures\footnote{Azzutti, Alessio, Ringe, Wolf-Georg, and Stiehl, H. Siegfried, « Machine Learning, Market Manipulation and Collusion on Capital Markets: Why the ‘Black Box’ Matters, » European Banking Institute Working Paper Series 2021, no. 84, University of Pennsylvania Journal of International Law, vol. 43, no. 1, 2021, SSRN, doi:10.2139/ssrn.3788872.




